Unit 2.1 Unit type, Population and Universe
Unit study time
- 25 minutes
Intended Learning Outcome
By the end of the unit, you will be able to ...
- Define Unit Type, Universe, Population, and explain how they differ.
- Describe how these elements contextualise variables and datasets
- Apply these concepts to a dataset to determine who/what is being measured.
- Explain how Unit Type/Universe/Population enable valid comparisons across datasets.
As demonstrated in unit 1.2, we need to describe what/who the data is about. We can do this by capturing Unit Type, Universe and Population metadata. These were briefly defined in unit 1.2, but we will now have a more detailed look at these, as well how they relate to each other.
The reason for being explicit about these terms is that they provide a way to understand:
- Who or what is being measured
- The characteristic of whom or what is being measured
- Where and when is was being measured
This can seem self evident, but if we want to validly combine or compare data (or at least know we are NOT comparing the same thing), these are important pieces of metadata which allow us to make valid or informed decisions.
Unit type
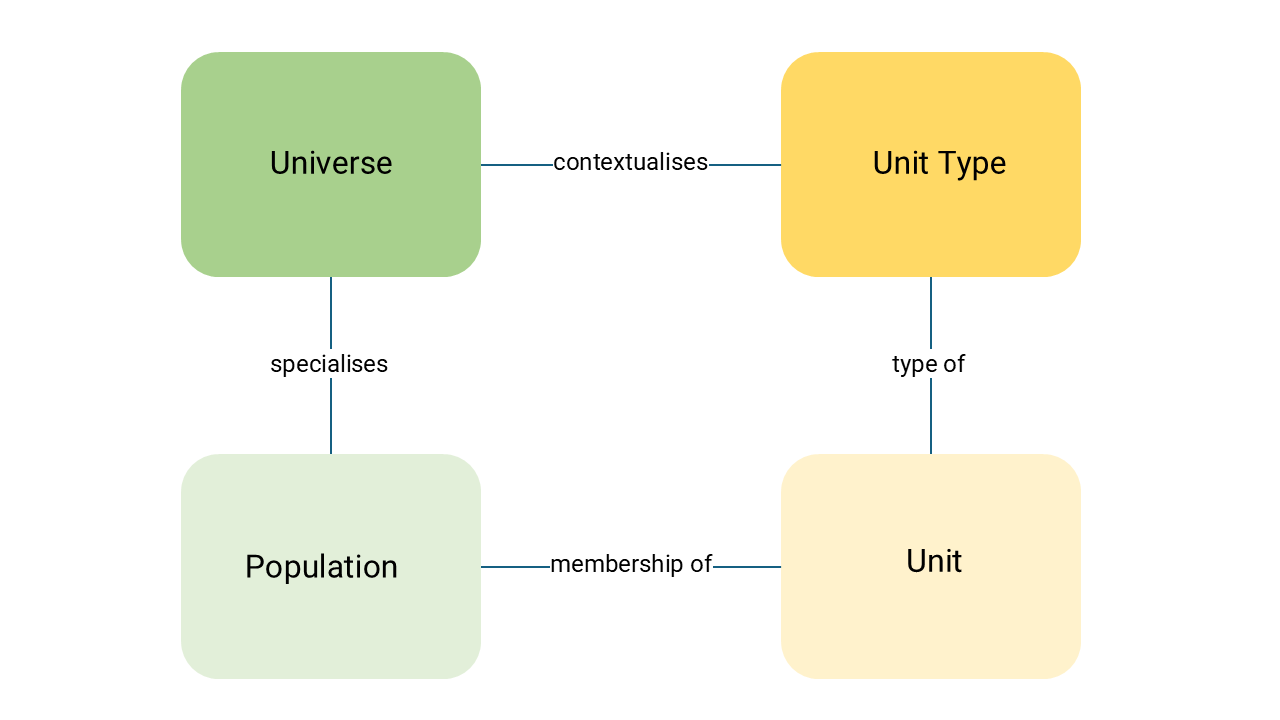
The Unit Type is type of entity being measured. It is the unit of observation or analysis in your research based on a single characteristic. It is usually a primary entity, for example: individual, household, establishment, country, dog, apple, maize plant. Variables are always attached to a unit type, as they are made up of individual units.
The Universe and Population help contextualise the Unit Type further.
Universe
The universe defines who or what is eligible to be within the study. Sub-universes can define who is eligible to answer a particular question or have a variable measured.
"A universe consists of all survey elements that qualify for inclusion in the research study. The precise definition of the universe for a particular study is set by the research question, which specifies who or what is of interest." Encyclopedia of Survey Research Methods (https://methods.sagepub.com/ency/edvol/encyclopedia-of-survey-research-methods/chpt/universe).
A universe is broad in nature as it is the set all units, from which a sample is to be drawn, although this can vary size (e.g. a survey of all individuals who have won 1 million dollars or more in the lottery is a much smaller universe than a survey of the television-viewing habits of all adults in the United States).[1]
Understanding the universe can help us decide if the data can be used for our research question or not. For example, if your research question was concerned with wind speeds in urban areas, a study with the universe "All wind speed and direction measurements recorded by research vessels" would not be able to help with your research. It could help with research about anemometer biases across research vessels instead, for example.
A Universe contextualises a Unit Type by providing additional characteristics, defining a certain group of people, objects, institutions or events.
For example...
- All individuals with a university degree
- All adults who could develop hypertension
- All retail business establishments
- All maize plants grown under drought stress
In this way, the Universe is the larger group that the study's conclusions might apply to.
A Universe may also be defined by what it excludes...
- All retail business establishments except charity shops
- All dogs without an owner
Population
The Population contextualises the Universe by specifying the experimental context, location, and timeframe. The Population is the specific subset of the Universe representing the actual group from which data could be collected i.e. the group which the units are drawn from at a specific time and place. The Population is operational and has a practically defined set of elements that are accessible, identifiable, and eligible for sampling.
For example:
- All individuals with a university degree living in Edinburgh in 1990
- All adults who could develop hypertension attending primary care clinics in Manchester in 2024
- All retail business establishments operating in London as of March 2025
- All maize plants grown under drought stress in Kenya during the 2024 growing season
Example dataset
| name | label | Unit Type | Population | Universe |
|---|---|---|---|---|
| f_n | first name | Individual | Adults aged 18-50 living in the UK as of 2016 | Adults aged 18-50 |
| s | sex | Individual | Adults aged 18-50 living in the UK as of 2016 | Adults aged 18-50 |
| h | height | Individual | Adults aged 18-50 living in the UK as of 2016 | Adults aged 18-50 |
| b_d | birthdate | Individual | Adults aged 18-50 living in the UK as of 2016 | Adults aged 18-50 |
| m_s | martial status | Individual | Adults aged 18-50 living in the UK as of 2016 | Adults aged 18-50 |
As these variables are from a single data collection point, the Unit Type, Population and Universe will be the same. If your whole dataset only collects data from a single source, then it is more efficient to capture the Unit Type, Population and Universe metadata at the dataset level.
What are the benefits of including Unit Type, Universe and Population metadata?
-
Improves transparency and interpretability. Clarifies what or who the data is about, as well as when. This gives us a clearer idea of the subject of the data, reduces ambiguity, and highlights limitations of the data.
-
Supports cross‑study comparison and data integration. As Unit Type and Universe are not defined by time or geography, you can more easily identify variables to compare with other similar variables from different datasets conducted at a different time and/or place. This encourages cross-study comparison, fuelling the potential for new research investigations from existing data.
-
Provides the foundation for assessing representativeness. The population defines the scope and representativeness of your data, and so is critical for understanding any sampling bias and for statistical inference. You cannot answer the question 'Does your sample reflect the characteristics of the population?' if you don't know the population. Population is the benchmark against which representativeness is judged.
-
Enables the detection of sampling bias. You cannot detect sampling bias unless the population is known. Any bias can only be evaluated by comparing sample vs population.
-
Allows valid statistical inference. When making inferences, you need to know the boundaries of the population so you can ask questions about that population and not beyond it. In the example above, you would not be able to generalise the data to infer crops in Wales.
Examples
The following examples show Unit Type, Population and Universe for different data collections, and how we can use this metadata to understand what the data is about, determine which datasets can be meaningfully compared, and identify which datasets are suitable for answering a particular research question.
Measuring income over time
Here, the unit type and universe are identical, so both datasets measure the same thing. The only difference is the time frame, meaning the datasets can be used to study change over time.
| Type | Dataset 1 | Dataset 2 |
|---|---|---|
| Unit Type | Individual | Individual |
| Universe | All employed adults aged 18–65 | All employed adults aged 18–65 |
| Population | All employed adults aged 18–65 in England in 2021 | All employed adults aged 18–65 in England in 2011 |
Measuring income across different geographical areas
In this example, time and universe remain constant, but geography changes. This allows comparisons across regions.
| Type | Dataset 1 | Dataset 2 |
|---|---|---|
| Unit Type | Individual | Individual |
| Universe | All employed adults aged 18–65 | All employed adults aged 18–65 |
| Population | All employed adults aged 18–65 in England in 2021 | All employed adults aged 18–65 in Wales in 2021 |
Measuring income for different universes
Here, the population is similar, but the universe changes. This alters the conceptual focus of the data collection.
| Type | Dataset 1 | Dataset 2 |
|---|---|---|
| Unit Type | Individual | Individual |
| Universe | All employed adults aged 18–65 | All unemployed adults aged 18–65 |
| Population | All employed adults aged 18–65 in England in 2021 | All unemployed adults aged 18–65 in England in 2021 |
These examples show that even when datasets look similar, differences in unit type, universe, and population can significantly affect how they can be compared and interpreted.
Test your knowledge
Which of the following best describes the “unit type” in a dataset?
- The geographic area covered by the study
- The type of entity that each record represents
- The time period of data collection
- The method used to collect the data
Reveal answer
The unit type refers to what each observation represents (e.g. individuals, households, organisations, plants).
A dataset includes responses to a question about employment status, but only for respondents aged 16 and over. What does this represent?
- The population
- The universe
- The unit type
- The sampling method
Reveal answer
The universe defines the subset to whom the question applies, in this case, respondents aged 16+.
How do clearly defined unit type, population, and universe support valid comparisons across datasets?
- They ensure datasets include the same variables and categories
- They help standardise how results are presented across studies
- They allow researchers to confirm that like is being compared with like
- They ensure that datasets are collected using the same methods
Reveal answer
Clearly defined unit type, population, and universe ensure that datasets are comparable by confirming that the same kinds of entities are being studied, the same groups are being targeted, and the same conditions apply. Without this, comparisons may be misleading or invalid.
Which of the following best explains the relationship between population and sample?
- They are always identical
- The sample is a subset of the population
- The population is derived from the sample
- They are unrelated concepts
Reveal answer
A sample is drawn from the population and used to make inferences about it.
Summary
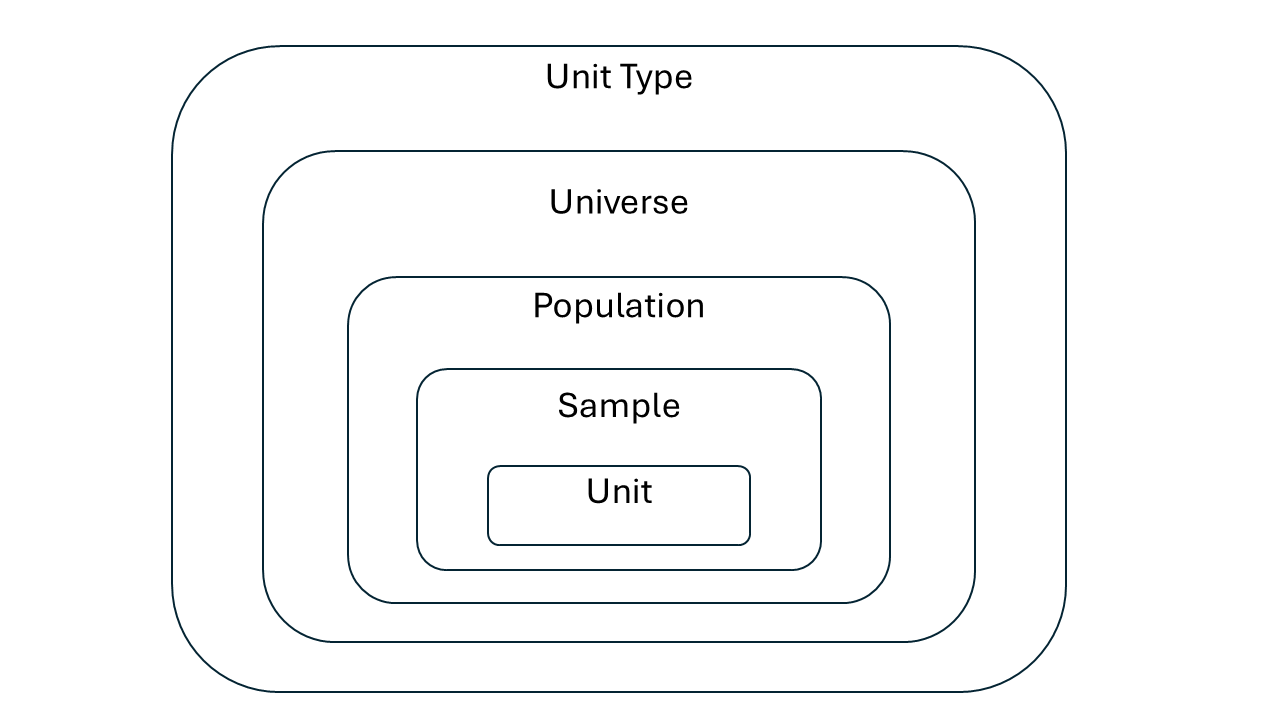
- Unit Type: The entity observed (e.g. plant, soil sample, individual).
- Universe: Is conceptual. It is the conceptual total—everything that fits the definition, whether or not it can be fully identified or listed (e.g. maize plants under drought stress, individual with degree).
- Population: Is operational. It practically defines a set of elements from the universe that are accessible, identifiable, and eligible for sampling. It adds time and geography and sometimes experimental context (e.g. maize plants sampled in Kenya in 2024).
- Sample: The actual subset collected within that population, based on the sampling framework. It is a collection of units (e.g. Plant ID 014 in Field A, Plant ID 015 in Field A and Plant ID 016 in Field A etc.)
- Unit: The actual individual entity in the dataset. The smallest element you observe (e.g. Plant ID 014 in Field A or Jane Smith). These could commonly be cases in a survey study.
 DDI Training Group. (2024, February 14). Foundational DDI Metadata: Unit, Unit Type, Universe, and Population. Zenodo. https://doi.org/10.5281/zenodo.10659410
DDI Training Group. (2024, February 14). Foundational DDI Metadata: Unit, Unit Type, Universe, and Population. Zenodo. https://doi.org/10.5281/zenodo.10659410
References
[1]Lavrakas, P. J. (Ed.). (2008). Universe. In Encyclopedia of Survey Research Methods. Thousand Oaks, CA: Sage.